emily x meschke
COMPUTATIONAL & COGNITIVE NEUROSCIENCE
image understanding
| Date | Focus / Experiment |
|---|---|
| Summer 2018 | Expanding receptive fields in face-selective areas. |
| Spring 2018 | How many faces can you recognize? |
| Fall 2017 | Population performance across face recognition tests. |
| Summer 2017 | Discriminating doppelgangers. |
| Spring 2017 | Detecting unspecified familiar faces. |
| Fall 2016 | Configural effects in face processing. |
| Summer 2016 | The perceptual deficit in congenital prosopagnosia. |
| Spring 2016 | Vertices aid perceptual grouping (and ungrouping). |
Expanding receptive fields in face-selective areas.
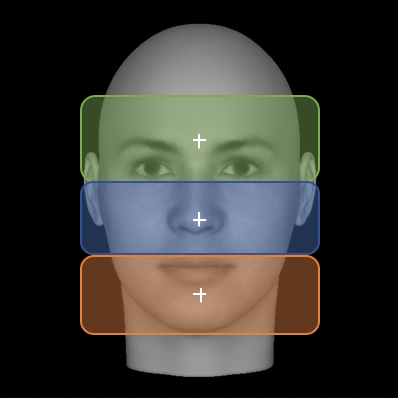
Faces are processed holistically, meaning that both the parts and the relationships among the parts provide information about the identity of the face. The theory championed by the Image Understanding Lab is that large receptive fields in face processing areas, such as the FFA and OFA, magnify small metric differences across the face, allowing for neurotypicals to account for these small variations. As Withoff et al. (2014) demonstrated that those with prosopagnosia have, on average, smaller receptive fields in face processing areas, this theory also explains why those with prosopagnosia have difficulties recognizing familiar faces: they lack the large receptive fields that would magnify small differences between similar faces.
This experiment was designed to behaviorally test whether those with prosopagnosia have smaller receptive fields. By controlling both the subjects' fixation and the coarse location of the feature changes between faces (upper, middle, lower), I will 1) test to see whether those with prosopagnosia perform worse than controls when the feature changes are further from fixation and 2) develop a training regimen to teach those with prosopagnosia to zoom-out, expanding the receptive fields in their face processing areas.
How many faces can you recognize?
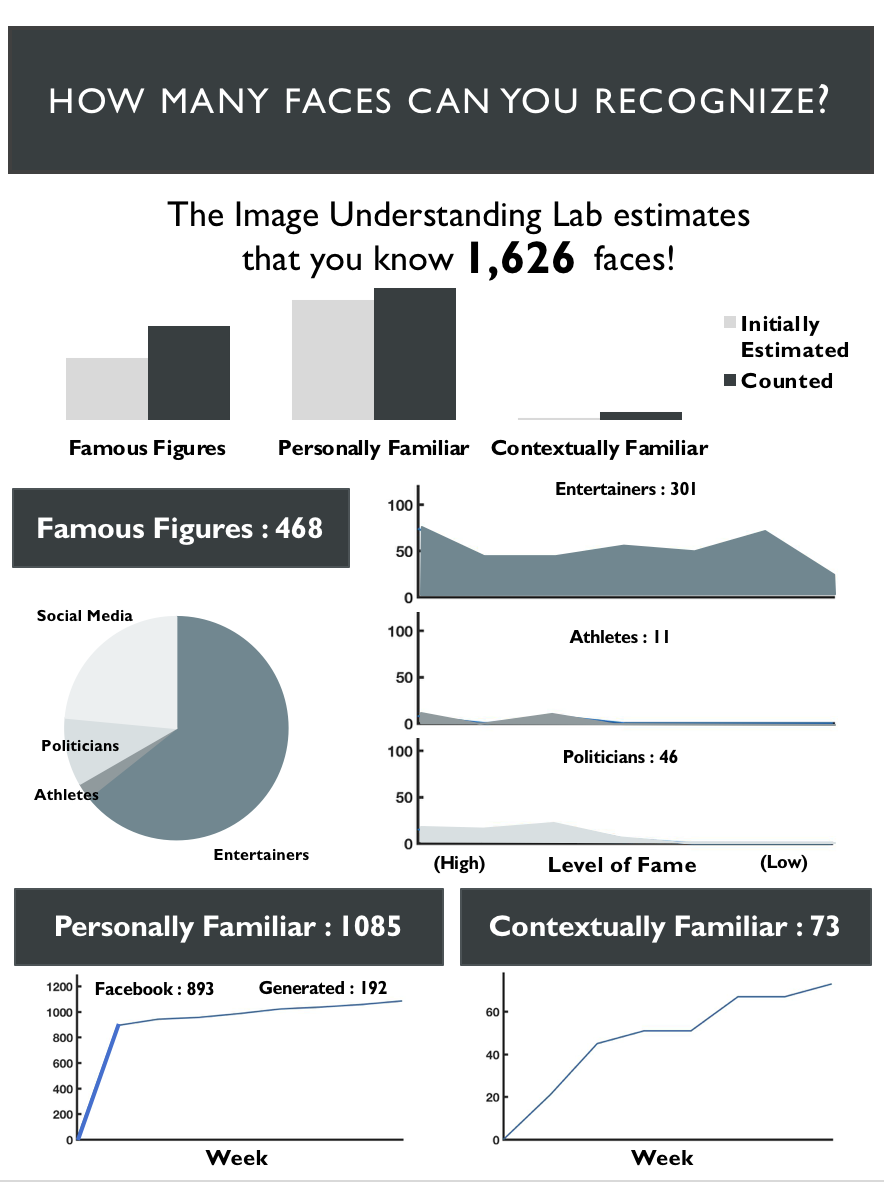
The short answer: about 1904.
The long(er) answer: I considered three classes of relations where we have an opportunity to learn a face:
- celebrities with which we have no personal contact
- personally familiar individuals with whom we have sufficient contact such as friends, coworkers, and family
- people we know from a specific context, such as a passenger on our usual bus route.
The sum of the three provides a lower-bounds estimate of the number of identifiable faces.
Population performance on face recognition tests.

Given how similar faces are to each other, people seem to have a remarkable capacity for face recognition.
Much of my work in the Image Understanding Lab has focused on figuring out ways to quantify people's ability to both perceive (above) and remember (below) faces. While there are many tests that "diagnose" prosopagnosia, in that those with prosopagnosia perform reliably worse than controls, many of these tests do not distinguish between potential causes. By tracking subject performance across mutliple tests, we can better isolate the reason for their deficit, whether it be perceptual, memory, or a combination of the two.
I've created and managed database of the results from multiple tests--including the USC Face Perception Test, the Cambridge Face Memory Test, and the PI20--for hundreds of subjects. I'm currently working with a software developer to design and create a database that automatically secures subject information, allowing the lab to collect and analyze subject data more quickly and efficiently. Check out some of the population results on the Image Understanding Lab website here.

Discriminating doppelgangers.
I developed a celebrity identification task that mimics real life face recognition. The only instruction is to identify which image is that of the celebrity, left or right. The non-celebrity faces were chosen to be as similar to the celebrity as possible in hairstyle, face shape, facial features, expression, and coloration--a doppelganger--to prevent those who struggle with recognizing faces from relying on non-face features for identification.
While this task is trivially easy for most neurotypical subjects, those with prosopagnosia struggle with the task, which demonstrates that small, ineffable differences between highly familiar faces somehow, with great precision, encode identity.
Try the test here! (It's fun, I promise)

Detecting unspecified familiar faces.
Even in situations with extreme uncertainty, face recognition is effortless, and in this experiment, we tested the temporal capacity for recognition. On each trial, a single celebrity--any celebrity--was shown in a sequence of 32 rapidly-presented headshots. The subjects didn't know if there was a celebrity in any particular sequence and, if one was present, who that celebrity would be or what the particular image would be.
Somewhat remarkably, subjects were able to detect the presence of a celebrity on 75% of the occurrences and, when a celebrity was detected, the subjects almost always identified the particular celebrity.
Check out the poster here.
Configural effects in face processing.
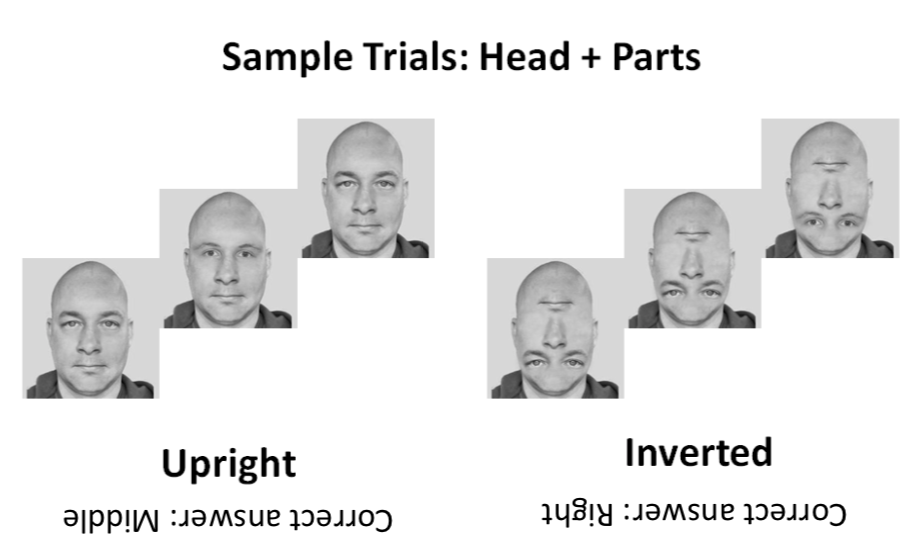
Many experiments have investigated the notion of a configural effect in face recognition, where the face parts provide more information in the context of a face than they do alone. In this experiment, we varied two factors: the ordering of the face parts and the presence of a head. It turns out that having the parts in a normal order resulted in a significant reduction in reaction time only when the parts are enclosed within a head.
Check out the poster here.
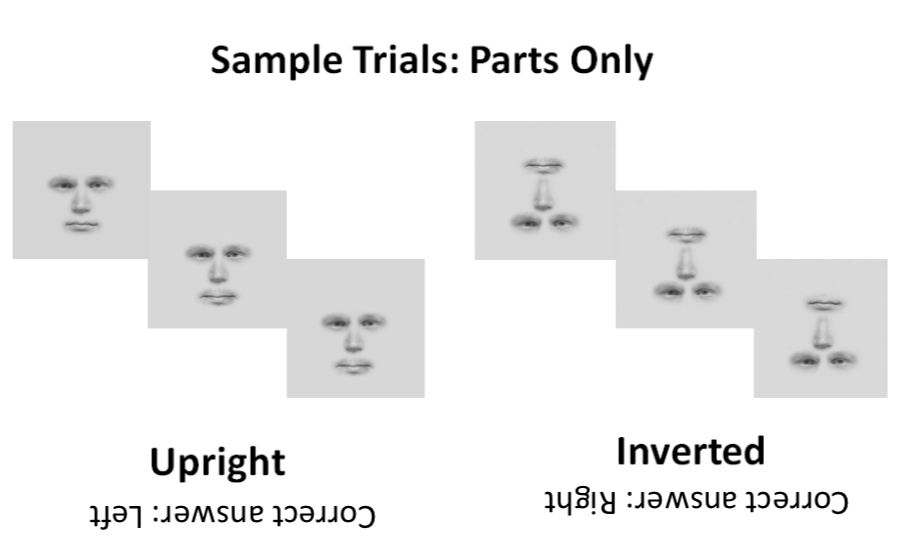
The perceptual deficit in congenital prosopagnosia.

Prosopagnosia is defined as the inability to recognize familiar faces. Using a match-to-sample paradigm, the Image Understanding Lab demonstrated this deficit has a perceptual component, as congenital prosopagnosics (CPs) are worse at discriminating both faces and complex, metrically varying shapes (blobs) but not simple geometric objects. Furthermore, there was little effect of a 4 second delay, indicating that the result is not due to a deficit with working memory.
Try it here!
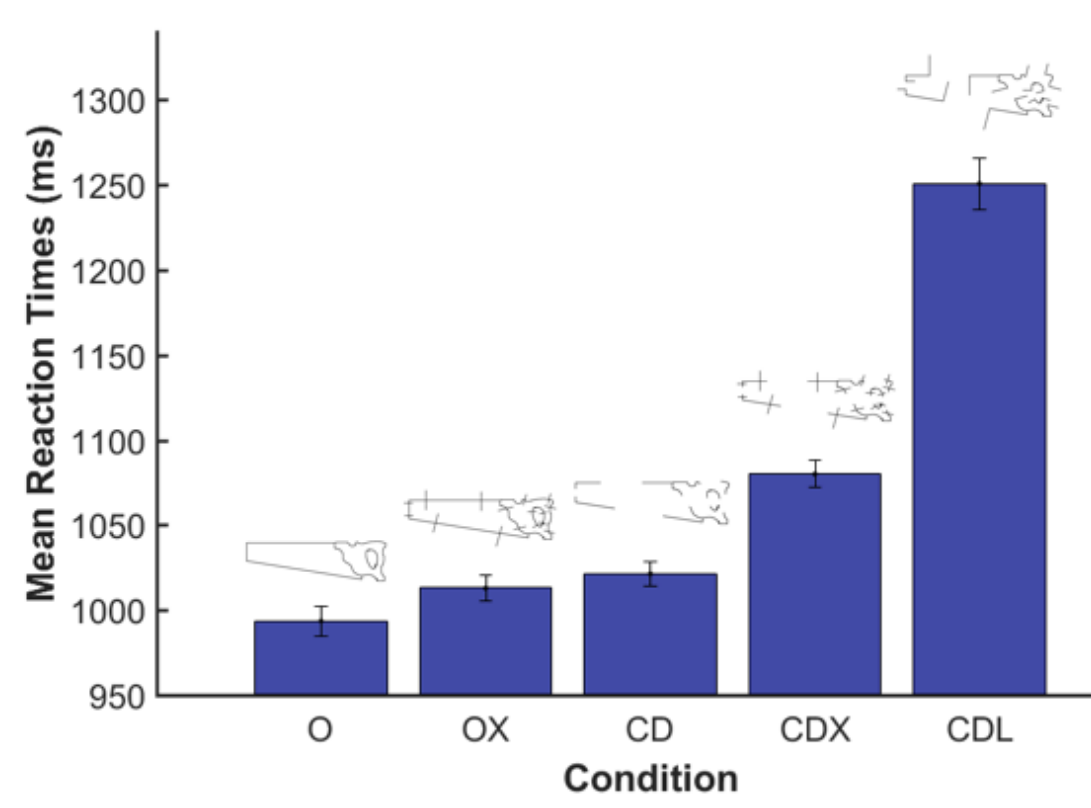
Vertices aid perceptual grouping (and ungrouping) in object recognition.
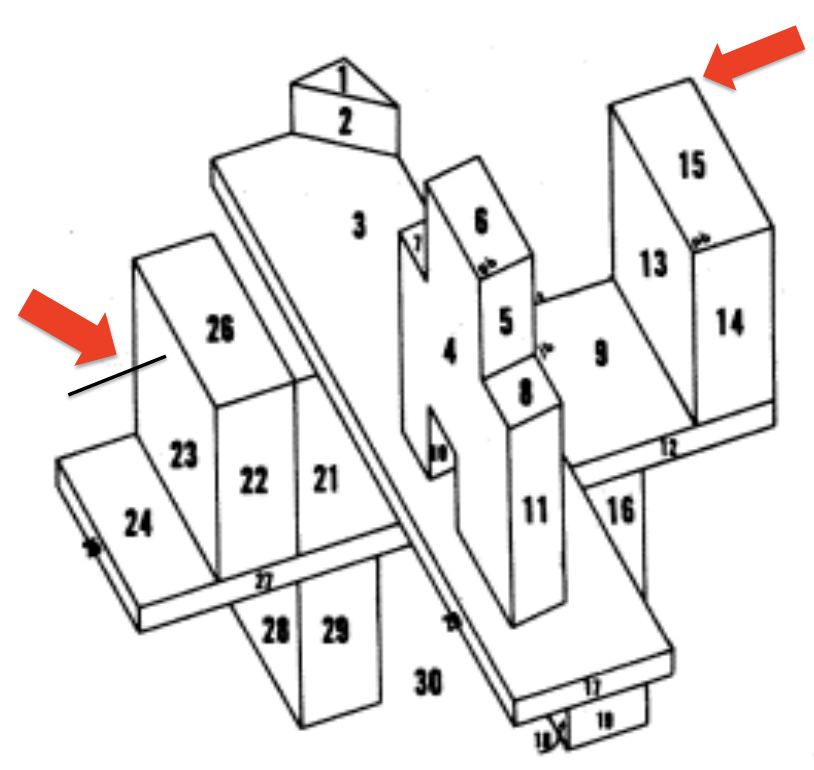
With only a brief glance, people are able to process and assess a complex scene, relying on the edges and vertices for most of the shape, and consequently object, information. Certain vertices provide more information about objects, with 'L' vertices indicating termination (top-right) and 'X' vertices providing useless noise (left). Thus, the 'L' vertices are more disruptive to object recognition, as seen in the reaction times.
Check out the poster here.